Abstract:
In 2020, on GitHub, more than 60 million new repositories were created by over 56 million users. There is a common understanding of the code base for hobby-project repositories or small-scale projects with few developers. Its “health” is relatively easy to attain and capture. However, the bigger software projects become and the more complex they become, the more management and oversight might help ensure code maturity and health. Especially large code bases impose new challenges and open up new opportunities for the automated analysis and visualization of the software data.
Therefore, we have developed a tool for the peer-group-based analysis of software repositories from GitHub, GitLab, or other sources. Our tool was developed and tested on over 1000 software repositories.
Setting:
The project described in the following was conducted as part of a masterproject with the title “Analysis and Visualization of Similarities in Software Systems” at the Computer Graphic System research group at Hasso Plattner Institute as part of my master’s degree together with Robert Schwanhold.
The project was conducted with Sereene, a startup focused on analyzing and improving software and software development practices.
The following is a short glimpse of what the end result looked like.
Approach: The approach we took can be divided into three steps: (1) the similarity search/peer group search, (2) the descriptive analysis, and (3) the prescriptive analysis. We considered over 1000 repositories for the project, which amount to over 300GB of data. These are composed of the top 1000 most liked repos on Github by language and a few extra repos - starred projects from project participants.

(1) Similartiy Search:
We considered READMEs and code files and their content to assess the similarity between two software repositories.
After extensive preprocessing, we either performed Latent Semantic Indexing or Latent Dirichlet Allocation on READMEs and code files (a sample of the overall number of files per repository to reduce computational effort for the similarity assessment). To have one consistent similarity score, we averaged the four scores.

For that, the user simply enters a repository for which a peer-based analysis should be performed. We also created a force-directed graph for multiple skip-level to deliver a broader view of the domain of repositories (stemming from the base repository marked with a darker grey dot).

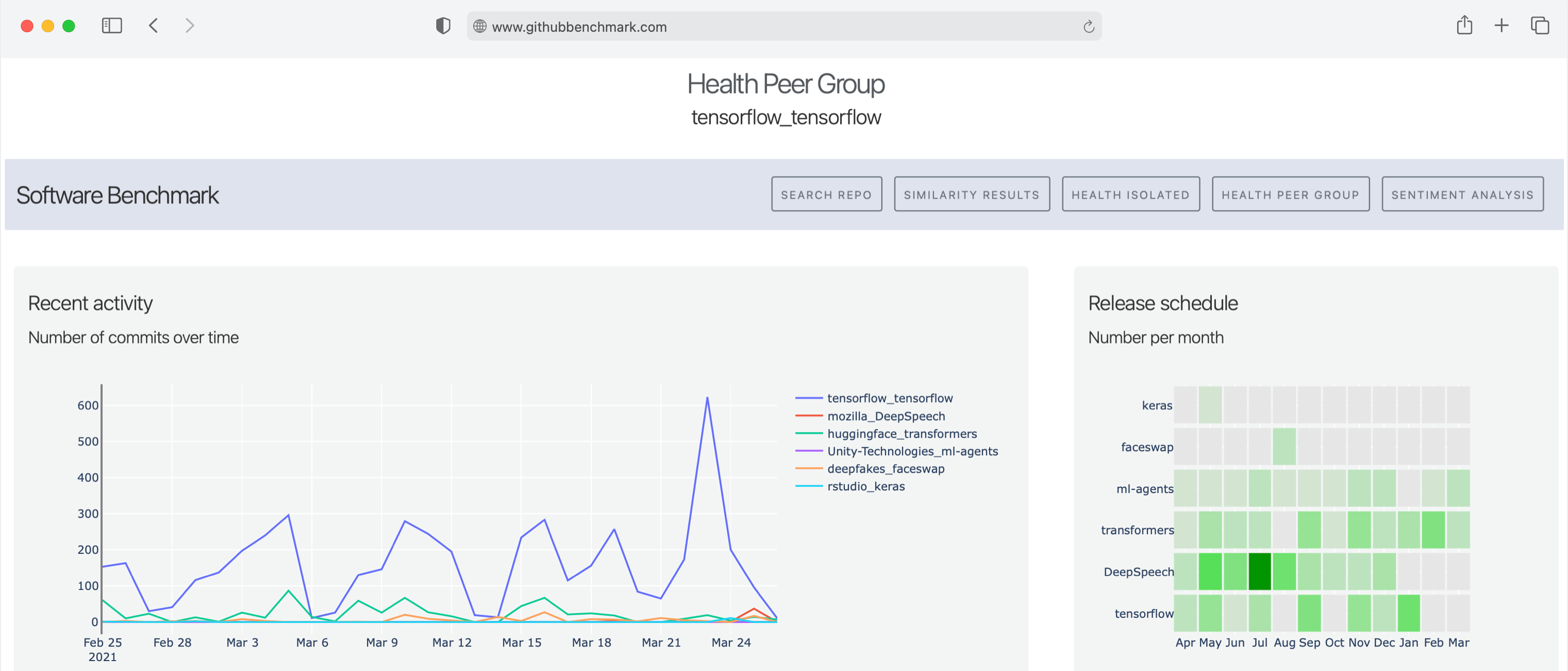
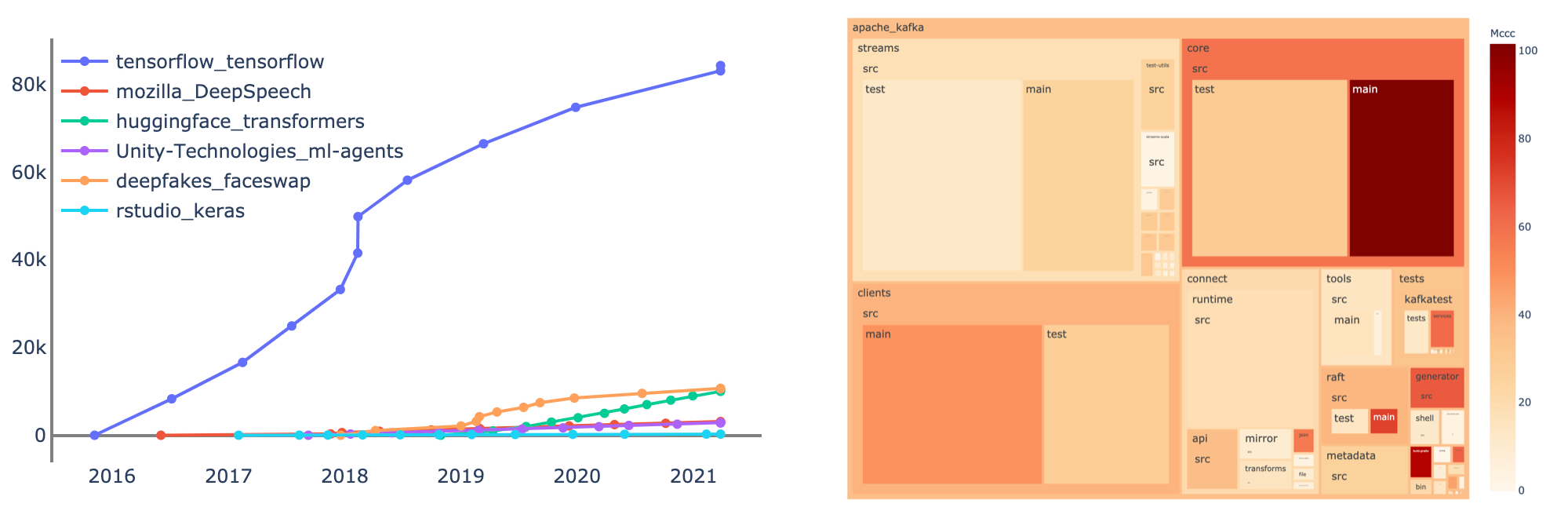
(2) Descriptive Analysis: After searching the most similar repository for a particular repository, we can perform a descriptive analysis. Amongst others, our descriptive analysis focuses on the stars, contributions, and forks over time, the release schedule of the software projects, as well as the distribution of comments and lines of code.
Furthermore, we created a dynamic treemap that can be used with the color indication representing, for example, the MCCC (McCabe Cyclomatic Code Complexity) across multiple files or parts of the repository - a common metric for analyzing code complexity and human readability.
(3) Prescriptive Analysis: Beyond a descriptive analysis, we also considered the developer communication in larger software projects to suggest points for intervention or timely assistance/troubleshooting by analyzing, amongst others, comments and issues relating to a code repository. For that, we used a sentiment analysis pre-trained on social media conversation (assumed to be similar to developer interaction) to find the most negative user voice to be able to intervene quickly.
The following shows an example derived from the Tensorflow repository on GitHub.

Summary: If I were to summarize the project on “peer-group-based software analysis & benchmarking”, I would summarize it as follows: The project had a length of approximately one semester, and for that (also given our small team size - of two students), we can be really proud of the results. The tool we were able to develop spanned from data acquisition to preprocessing and analysis of large volumes of data (> 300GB) to a visually appealing and well-structured web app for easy analysis and benchmarking of software repositories across multiple dimensions.