Abstract:
Heart failure is one of the leading causes of hospitalization and rehospitalization in American hospitals, leading to high expenditures and increased medical risk for patients. The discharge location has a strong association with the risk of rehospitalization and mortality, which makes determining the most suitable discharge location for a patient a crucial task. So far, work regarding patient discharge classification is limited to the state of the patients at the end of the treatment, including statistical analysis and machine learning. However, the treatment process has not been considered yet. In this contribution, the methods of process outcome prediction are utilized to predict the discharge location for patients with heart failure by incorporating the patient’s department visits and measurements during the treatment process. This research and the accompanying paper outline that, with the help of convolutional neural networks, an accuracy of 77% can be achieved for the hospital discharge classification of heart failure patients. The model has been trained and evaluated on the MIMIC-IV real-world dataset on hospitalizations in the US.
Setting:
The research described in the following was conducted as part of a seminar called “Advanced Topics in BPM Research” as part of my master’s degree at Hasso Plattner Institute together with Maximilian König, supervised by Jonas Cremerius and Prof. Dr. Mathias Weske.
Dataset:
We used the Medical Information Mart for Intensive Care (MIMIC)-IV database as the dataset to predict discharge location. The database is publicly available on PhysioNet (authorized access due to privacy regulations-see license). It contains information on more than 40,000 patients admitted to Beth Israel Deaconess Medical Center in Boston, Massachusetts, from 2008 to 2019.
The MIMIC-IV dataset consists of 35 tables that include the following patient data: Patient demographic information such as age and marital status, transfers between departments during their stay, and the medications they received in each department. In addition, various information on diagnoses is provided, such as ICD (International Classification of Diseases) codes, DRG (Diagnosis-related Group) codes, and laboratory values resulting from the patients’ laboratory tests, such as hemoglobin, creatinine, and urea nitrogen values.
After preprocessing the dataset, we are left with a three-dimensional dataset shape, as shown in the following picture (for different patients, across different timesteps with multiple features such as the time spent in a particular department or laboratory values).
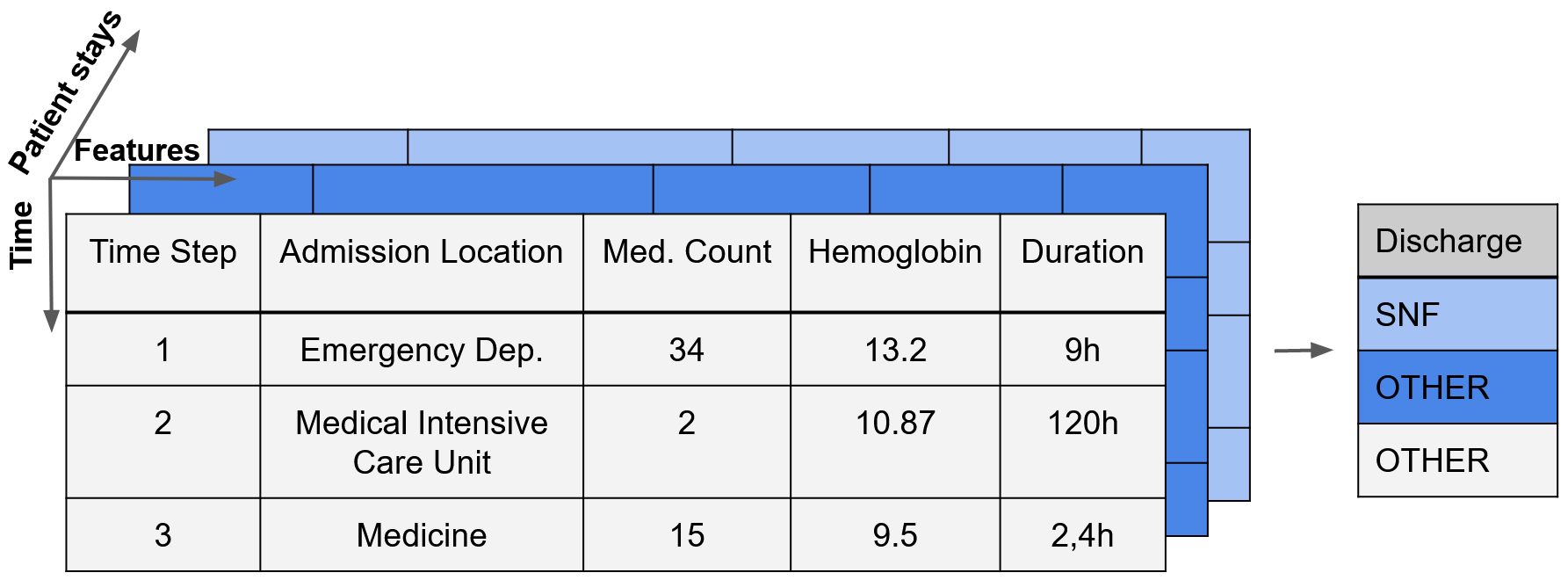
Process Outcome Prediction:
“Business Process Management (BPM) includes concepts, methods, and techniques to support the design, administration, configuration, enactment, and analysis of business processes” .
Business process monitoring is a subset of business process management and provides means for analyzing events that occur during process execution, enabling insights into the overall process and its improvement. A subbranch of business process monitoring, predictive business process monitoring, aims to make predictions about future states of current process execution based on previously executed activities and other previously executed process instances.
One technique that has evolved in this field in recent years is process outcome prediction. According to Teinemaa et al., it can be defined as “classifying each ongoing case of a process according to a given set of possible categorical outcomes” . The advantages of predicting process outcomes early in the process execution are better predictability and the potential to improve decision-making during process execution .
Convolutional Neural Network:
Convolutional Neural Networks (CNNs) are deep neural networks that are commonly used for sequence classification tasks and process outcome prediction . Originally, CNNs became popular for pattern recognition in, for example, computer vision tasks, i.e., the analysis of images. A CNN architecture comprises three elements: convolutional layers, pooling layers, and fully-connected layers. Convolutional layers perform convolutions using kernels of different sizes to extract relevant high-level features from the input data, reducing dimensionality. Pooling layers are used to perform down-sampling to reduce the complexity for subsequent layers. In fully-connected layers, each node
has a direct connection to every node in the next layer up to the final layer, that finally produces the output .
An exemplary CNN architecture is shown in the following (own illustration).

Research Approach & Contribution:
The contribution here is summarized but can be found in full detail in the published paper. Overall, the contribution can be summarized into the three main parts:
- Cohort Selection: Overall, the MIMIC-IV dataset includes various patients. However, we focussed on hospital discharge location prediction for heart failure patients. Heart failure is defined as “a complex clinical syndrome
that can result from any structural or functional cardiac disorder that impairs
the ability of the ventricle to fill or eject blood” .
The cohort of patients was selected based on the diagnosis and the DRG of the hospital stay to identify patients where heart failure was treated. The dataset stores diagnoses as so-called ICD codes. Thus, we selected all patients who had a heart failure related diagnosis as their primary diagnosis.
- Feature Selection and Data Preprocessing: Given the set of features, the raw data had to be preprocessed to fulfill the shape and data type requirements of the models to train. For example, categorical features such as the department visited, gender, and marital status were one-hot encoded to represent them as numerical values that can serve as input for machine learning analyses. This also prevents the introduction of non-existent ordering between the items. Furthermore, all numerical features were standardized by scaling them to zero mean and unit variance.
- Model Selection and Preprocessing:
We chose CNNs as our model architecture and trained all models on the preprocessed data for patient discharge classification. We performed training on other models as well, such as LSTM and XGBoost, while CNNs turned out to provide the best results on this particular dataset. In order to get the best model, we then applied hyperparameter tuning. We defined multiple hyperparameters such as the kernel sizes of the convolutional layers, the size of the fully connected layers and pooling layers, and the intermediate activation functions.
The best model parameters were chosen based on the F1-score on the validation part of the dataset. The models were then analyzed using accuracy, precision, recall, and confusion matrices.
Result:
The code to reproduce the results can be found on GitHub. Please note that due to data privacy restrictions for the MIMIC-IV database, you will have to get access to the database.
The final CNN model reaches an accuracy of 77% with a weighted precision of 81% and a weighted recall of 77%, respectively. The F1-score is 0.78, and the AUROC is 0.73. As shown in the confusion matrix in the following, there is a discrepancy of about 14% between the accuracy of predicting SNF as discharge location on the one hand and the accuracy of predicting other discharge locations on the other hand.

The following chart shows the feature importance of our model as a beeswarm plot using SHAP values (SHapley Additive exPlanations) . The graph was generated using the SHAP library. It shows the impact of the 18 most influential features. Each dot for each feature corresponds to a single patient stay. The x-axis shows how much impact those features had, with high negative values indicating a high impact on the decision to SNF as discharge location and high positive values indicating the opposite. The color of a dot represents the value of the feature, red represents a high value, and blue a low value.
Since our data had a three-dimensional shape, which could not be represented in this graph, we averaged the SHAP values and the feature values for each patient stay.

For example, the distribution of dots for the patient’s age shows that a higher age often serves as a predictor for discharge to SNF.
Discussion and Future Work:
- Incorporation of treatment process improves prediction results:
Our work suggests considering the treatment process in classifying the discharge location of heart failure patients. Looking at the feature importance, features changing throughout the process have a significant effect on predicting the discharge location.
- Confirmation of relevant factors for discharge prediction:
Additionally, we were able to confirm relevant factors as proposed in current literature, which include age, insurance, length of stay, gender, and laboratory values (creatinine, urea nitrogen, and hemoglobin). Information about the availability of an informal caregiver is provided in the form of the marital status in the MIMIC database, which constitutes a relevant factor . However, marital status is only an indicator and does not represent the guaranteed availability of an informal caregiver.
- More features on the patient’s stay: As future work, a more detailed view of the process could improve the results of our model, as we did not incorporate a comprehensive view of the patient’s diagnoses, medications, laboratory values, and the procedures performed on them. Additionally, the mental status and further sociodemographic information could help to improve the model’s performance.
- Larger sample size: We assume that better predictive performance could have been achieved with larger sample size, as a sufficiently large sample size can significantly impact the predictive performance of machine learning models .
Conference & Publication:
Publically available in the Book Process Mining Workshops (ICPM: International Conference on Process Mining) by Springer. Furthermore, the paper is available on ResearchGate. We also got the opportunity to present our research and our paper at the International Conference on Process Mining 2021 at TU Eindhoven, Netherlands in October 2021.